Background
In February 2024 Subsurface Insights (in collaboration with Dr. John Bargar at PNNL) received a DOE SBIR award (DE-SC0024850) for a proposal in response to topic 17a (Complex Data: Advanced Data Analytic Technologies For Systems Biology And Bioenergy) of the FY2024 Phase I release I SBIR call. After successful completion of the Phase I efforts at the end of 2024 and submission of a Phase II proposal in December 2024 Subsurface Insights was selected for a Phase II award for this effort in June 2025. Funds for this award were received in September of 2025 and the project team is currently working on this effort.
Our proposal initially (and still) addressed needs defined by BER’s Biological Systems Science Division (BSSD) related to how to create sustainable production systems for biofuels and bioproducts. Biofuels are a critical part of the US energy strategy – see e.g. the recently released 2023 Billion Ton Report. There are numerous challenges associated with going from feedstocks to biofuels and bioproducts at scale and in a cost efficient manner. These challenges (which within DOE are for a large part addressed within four Bioenergy Research Centers) can be roughly grouped in the four research thrusts shown below.
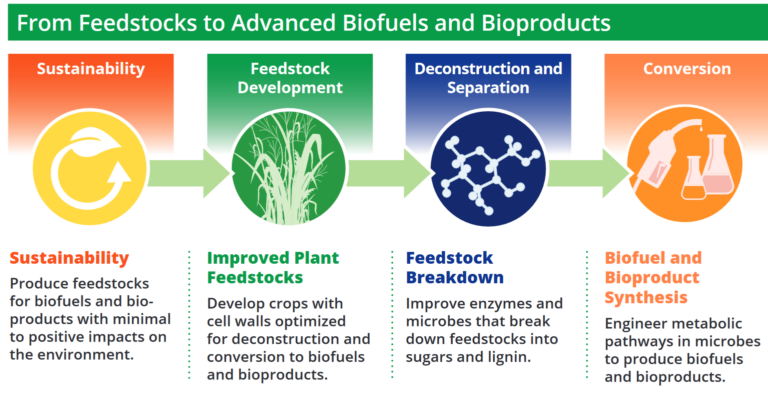
Four different research thrusts associated with the research done by DOE scientists. Figure source: Bioenergy Research Centers 2022 Program Update (page 3).
Initial need addressed by our proposal
The initial need addressed by our proposal is related to the first research thrust shown above: Sustainability, and specifically the need for optimal feedstock development. Selecting and developing site specific optimal feedstocks requires knowledge and insights about the complex multivariate interactions between crops and their environment, impacts of crop choice and management systems, and key plant-microbe-environment interactions.
The increasing availability of large bioenergy crop, soil and environmental data sets promises major new opportunities to obtain this knowledge by fusing and analyzing this data to discover constitutive relationships that link key parameters such as genotype and soil microbiome to crop yield and water stress resiliency.
As is shown in the figure below, this data is multimodal and multiscale. It includes high throughput plant phenotype data, multi-omic data from plants and soils, and imagery over scales ranging from molecular (e.g., protein structure models) to plot scale (e.g., Phenocam and drone data) to tens of meters (i.e., green normalized difference vegetation index (GNDVI) from satellite data). Critical ancillary data include soil types, topography, and environmental conditions (precipitation, solar radiation and air and soil temperature). Our SBIR project is developing tools for fusing and analyzing this data and in Phase I we demonstrated the applicability of our approach to data from the GLBRC Biofuel Cropping System Experiment . An article describing our results (including access to our code base and data) is forthcoming (Ahkami et al, 2026).
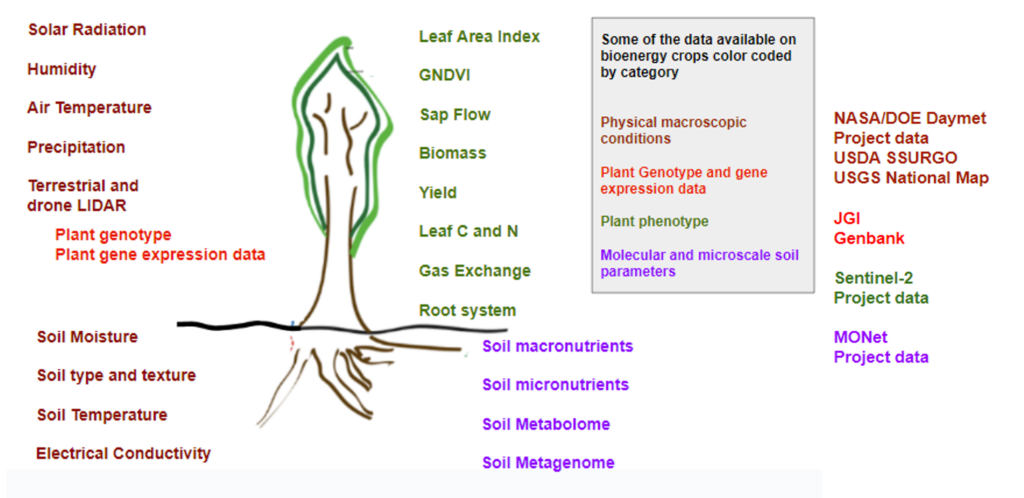
Some of the different data sets associated with bioenergy crops. These datasets are multimodal and multiscale and can be categorized and grouped in different ways. One possible grouping and some of the sources are shown. Figure inspired and modified from (Venturas, Sperry et al. 2018)
SBIR approach
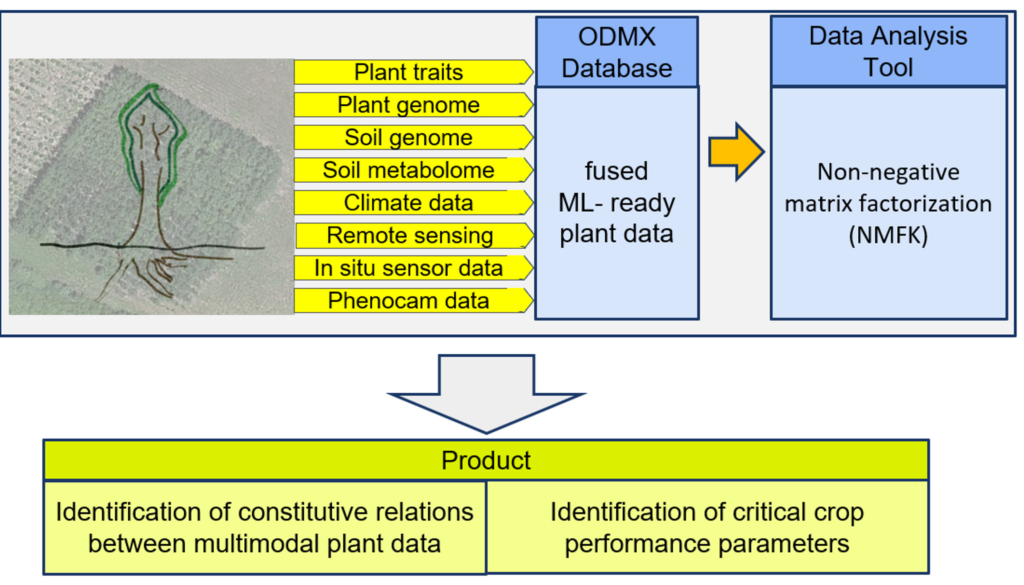
Phase I Approach : we fused multimodal biofuel crop data into an ODMX Database, implemented ML-guided analysis capabilities and demonstrate the application of the analysis tool on data from the GLBRC Biofuel Cropping System Experiment
Project detail, progress, developments and opportunities for collaboration
The software which will be developed in this project will be open source. At the core of this software is the open source ODMX information model and associated cyberinfrastructure, but there is additional software and tools we are releasing which complements and enhances this software. An initial version can be found here. We will provide periodic releases of this software.
As this is a SBIR funded project (and thus is meant to lead to a commercial capability), the plan of Subsurface Insights is to provide this software to interested users under a SAAS (Software as a Service) model. Thus, while groups would be able to install and deploy the software themselves, they could also contract with Subsurface Insights to provide this software and support for it. We target a first release for this capability around the 2026 AGU meeting in December 2026.
Currently (March of 2026) the team (consisting of staff from Subsurface Insights and PNNL) is working in rapid sprints on iteratively enhancing enabling cyberinfrastructure, data harvesting and ingestion pipelines and data imputation and analysis codes. We are working with six different DOE funded projects who all have a wealth of heterogeneous data to test, validate and enhance our approach.
While our effort continues with the approach outlined in our proposal and described above we are also ensuring that our effort remains relevant to recent development. Specifically, one of the main developments in the last years is of course the emergence of generative AI.
Generative AI and agentic workflows accelerate discovery. However, to answer the most important questions in systems biology – questions which cannot be answered using a single data type or data from a single domain – we need unstructured and heterogeneous data from multiple domains.
This includes landscape information (topography, slope, soil type), data on forcing (precipitation, wind, temperature, humidity, solar radiation), vegetation information (phenotypes, diversity, senescence, sap flow, productivity), soil properties (grainsize, minerology), omics of plants, soils and water (metagenomics, metatranscriptomics, proteomics, metabolomics), aqueous geochemistry, information on dynamics and fluxes from different sensors (temperature, soil moisture, time lapse electrical resistivity, satellite imagery). We can have hundreds of different data types across multiple science domains. Some of this data is continuous and dense. Other data is sparse. Some data integrates properties over tens of meters. Other data measures a property extremely locally. Some observations are directly related (e.g. aqueous geochemistry dynamics and time lapse electrical resistivity data), whereas other data (e.g. yield) are a complex function of other data. We need to provide semantic linking and ontology mapping, as well as capabilities for assigning confidence, quality and trusted imputation approaches.
This need makes our project even more relevant as we build the data fusion tools and quality verification pipelines that encode cross-domain data relationships and provide an auditable and trusted foundation for agentic scientific discovery. As the PNNL scientists involved in this SBIR are at the forefront of the use of agentic discovery we are leveraging their insights to ensure that the capabilities developed here are directly relevant to the generative AI needs.
Opportunities for collaboration